


- Privacy Policy
- Terms & Conditions
- Contact us
- ©Isabel Healthcare 2025
October 26, 2016
2) Symptom Checkers Aren’t Made for Doctors
3) Not All Symptom Checkers are Created Equal




 A new article and study appeared recently entitled “Comparison of Physician and Computer Diagnostic Accuracy” in the Journal of the American Medical Association (JAMA). The study took clinical cases and data from a 2015 study, and compared the accuracy of patient oriented symptom checkers with physicians’ diagnoses of the same cases. We wrote a blogpost back in 2015 on the original study, which tested the diagnostic accuracy of 23 symptom checkers, including ours. As indicated in the previous blogpost, we felt the study had some major limitations, and we have similar, serious concerns with this follow up publication over its purpose and conclusions.
A new article and study appeared recently entitled “Comparison of Physician and Computer Diagnostic Accuracy” in the Journal of the American Medical Association (JAMA). The study took clinical cases and data from a 2015 study, and compared the accuracy of patient oriented symptom checkers with physicians’ diagnoses of the same cases. We wrote a blogpost back in 2015 on the original study, which tested the diagnostic accuracy of 23 symptom checkers, including ours. As indicated in the previous blogpost, we felt the study had some major limitations, and we have similar, serious concerns with this follow up publication over its purpose and conclusions.
Symptom checkers and differential diagnosis tools like Isabel were created to improve the diagnostic process globally, not to replace the art of diagnosis practiced by clinicians around the world. This study’s entire purpose and its limitations make it, at best, completely counter-productive to the cause of improving diagnosis and, at worst, pointless. We’ve put together our 5 main reasons why symptom checkers won't and can’t replace doctors, and discuss the limitations of the study at the same time.
1) Doctors Diagnose
The entire objective of this study was flawed from the beginning. Who said we should replace doctors? Trying to compare the efficiency of any diagnostic tool with a professional, whether a consumer oriented symptom checker or a differential generator for professionals, is senseless, because they were never designed to replace a doctor but to make him or her smarter. Isabel exists because we wanted to make it easier for physicians to recall and utilize the knowledge and skills they have learnt at medical school, and to help them in thinking through diagnostic possibilities to broaden and build their differential. Isabel does not exist because we wanted to find an alternative to a doctor. This study tries to prove something that was never in question in the first place.
2) Symptom Checkers Aren’t Made for Doctors
There is also a core difference between symptom checkers and professional differential diagnosis (DDx) generators. Isabel provides both, and we know just how different they are. Symptom checkers are designed to help patients make sense of their symptoms and aid a fruitful discussion with their health care providers. DDx generators are aimed at healthcare providers using evidence-based medicine, to help them broaden or formulate their differentials. This study pitches symptom checkers against doctors, not DDx systems. Symptom checker tools, websites, and apps are not designed to be used by doctors, and comparing the two with each other does not make sense.
3) Not All Symptom Checkers are Created Equal
The study uses result averages of 23 symptom checkers reviewed in the 2015 study to compare to physicians' findings. The authors state that the symptom checkers listed the correct diagnosis first 34% of the time, but the actual results ranged from 5% to 50%. On average, 51% of results had the correct diagnosis in the top 3, but this had a range of 29% to 71%. How useful is it to compare physicians to the average of a mixed bag of systems which are so completely different? Physicians’ skills vary, but we wouldn’t say all physicians are bad because some are. Symptom checkers’ capabilities vary even more, so why should they all be tarred with the same brush?
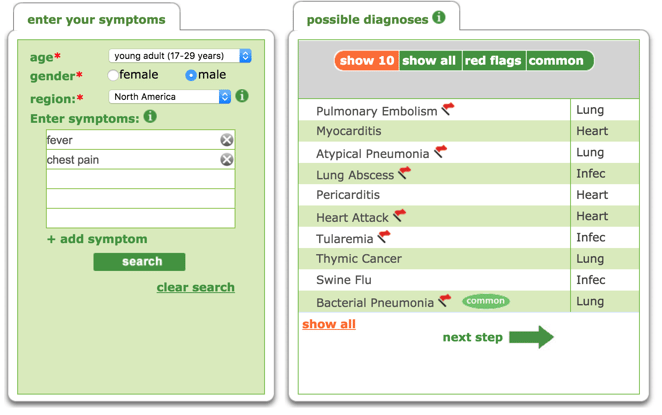
The study states the tools they used required the user to answer a series of questions, then the user is given a rank-ordered potential list of diagnoses. This is not the case for all symptom checkers or differential diagnosis tools. The best tools are quicker to use and allow symptoms to be entered in free text and natural language, as well as using medical terminology. The user should not be forced to pick from a list of symptoms or to select a portion of an avatar. They should be able to enter exactly what they are experiencing in their own terms, as you can see below on the example of Isabel's symptom checker. These symptoms entered then return a list of diagnoses based on the match of the symptoms within the database. With Isabel, this list is purposefully not ranked for a specific patient, as this is impossible without contextual information, which is added by the physician.
4) Cases are always different and complex
The clinical cases used in this study are the same medical vignettes used in the original study from 2015. In both studies, the cases were not suitable for the task required of them.
Firstly, the cases were clinical and, therefore, designed to be viewed by a medical professional, but were interpreted into data for the symptom checkers by just two non-clinical people. This data was then entered into the various symptom checkers in an effort to see where on the list returned the known final diagnosis would appear. The variability is tremendous in this instance, as each person’s interpretation of the case would be different and each symptom checker uses various methods of data entry for returning results. Compare this to the work of the physicians in the study, who simply interpreted the original cases and returned their diagnoses in natural language to be assessed, and there were 20 physicians to each case, giving a much larger pool of answers to go by. While the physicians were allowed to simply do their job, the symptom checkers had to try and decipher meaning from the vignettes extracted, all with varying methods and algorithms, and come up with the same accuracy as the physician, which is just not what they were designed to do. In some cases, the data extracted from the clinical vignettes included negative features which would be completely misinterpreted by tools using statistical natural language software such as Isabel; but how many patients would tell the doctor of symptoms he/she didn’t have anyway?
Secondly, the data used were standardized cases, which are often used in studies, as they allow users to define and analyse specific elements in a controlled environment. However, in the real world, no case is actually like this, because ‘cases’ are actually ‘people’ with stories, lives and memories of what has happened to them. Asking an algorithm or a doctor to interpret a standardized case has serious limitations, as they will not reflect real cases.
5) Symptom Checkers Need Doctors - and vice versa
Whether the study used symptom checkers or differential diagnosis tools, it would still be true that neither of these tools were designed to compete with or replace doctors, but instead to help them. Symptom checkers and differential diagnosis tools alike should coexist, aiding the patient to make sense of their symptoms, and the physician to expand their thinking and seek further information to reach a diagnosis or diagnoses. The tools need doctors in order to reach their full potential, just as doctors need the tools to reach theirs.
Take a look at our symptom checker for patients, and our differential diagnosis generator for medical professionals:


Jason Maude
Jason is the CEO and Co-founder of Isabel. Prior to co-founding Isabel, Jason spent 12 years working in finance and investment banking across Europe. His daughter, Isabel, fell seriously ill following a misdiagnosis in 1999 and this experience inspired Jason to abandon his city career and create Isabel Healthcare Ltd.